Palantir数据集成
Palantir平台提供了多种方法来集成系统中的数据,我将在这里将作详细说明。提供的集成方法如下:
- 前端导入(Front End Import/FEI)
- Kite导入/同步导入
- Raptor
- Phoenix
- 开发插件
前端导入是大多数分析师导入数据到Palantir的方式。操作前端导入,有多种选择:
-
点击“导入”按钮 – 将打开“文件导入对话框”,用户可以选择文件和文件夹进行导入;
-
拖拽到分析图或导入按钮 - 这将打开“文件导入对话框”,用户可以选择文件和文件夹进行导入,放置进去的文件将已经存在于选择区中;
-
将文件复制到剪贴板,右键单击“导入”按钮,选择“粘贴为新数据源” - 这将打开“文件导入对话框”,用户可以在其中选择要导入的文件和文件夹,放置进去的文件将已经存在于选择区中。也可以直接复制纯文本内容然后粘贴作为新文档导入到Palantir中,这种方式对剪辑网页数据是很有用的。
前端导入使用爬取(Crawl)、抽取(Extract)、检测(Detect)、转换(Transform)(CEDT)架构将文档导入Palantir,根据文档类型来执行必要的操作。这种导入技术可以扩展,有用于创建CEDT插件的API接口 。由于版本v3.6不支持OOTB,我曾使用CEDT创建了一个扩展来导入.msg文件,如果检测器识别了导入文件的格式,则将显示一个表示该文件类型的图标:
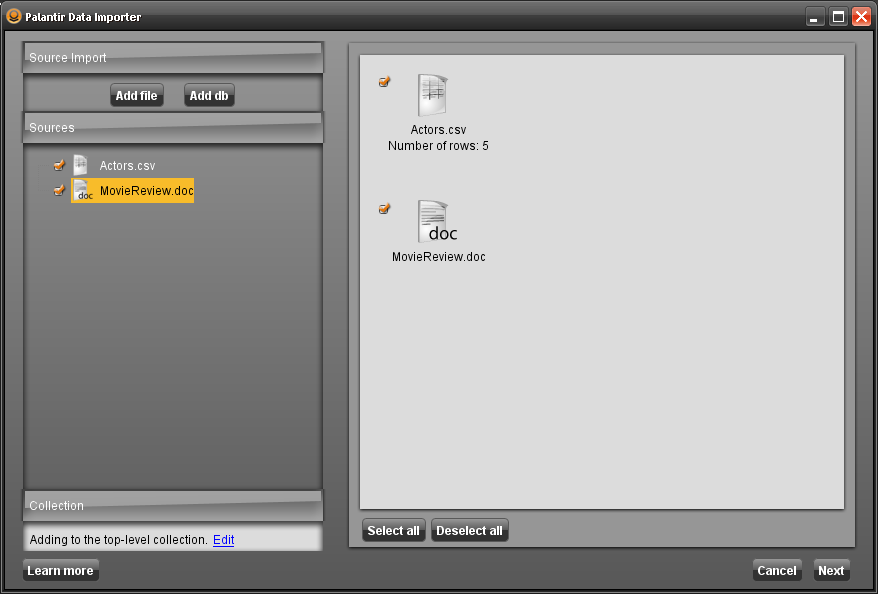
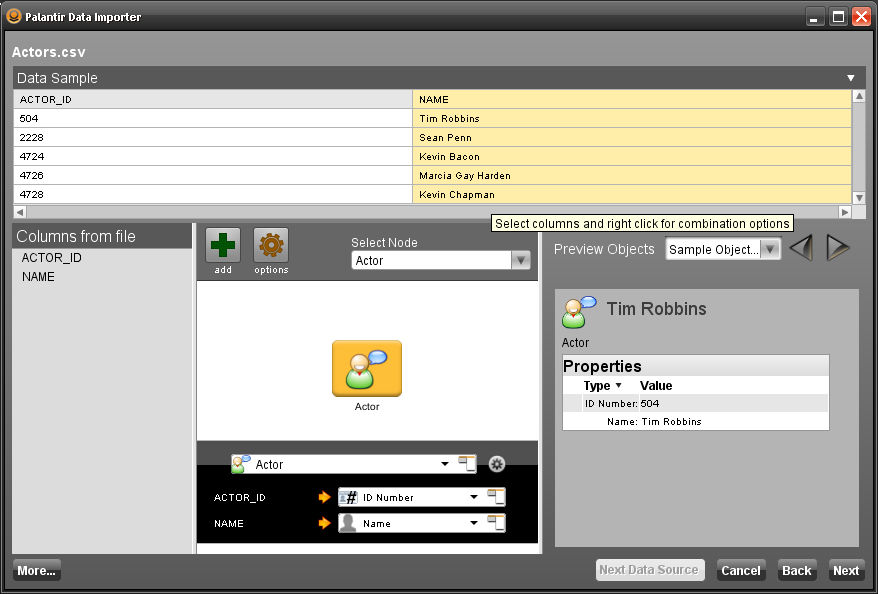
如果数据源被识别为结构化的(excel,csv等),则将出现一个映射对话框,允许用户对表列与属性进行映射,并且还对由于处理数据表而应该创建的对象和关联进行模型。
如果数据源是非结构化的,默认情况下直接导入到系统中,当然也可以创建一个CEDT扩展来处理源并自动标记内容。
Kite导入/同步
Kite是Palantir提供的应用程序,它将结构化数据源转换为一种pXML中间格式,它描述了对象、属性、权限等级、附件和关联。工程师需要创建一个Kite XML配置以描述数据源的结构、如何解析数据项的详细说明、并定义输出对象讲如何组装。
Kite配置有三个关键的部分:
- config
- rowprovider
- rowprocessor
Kite配置由XSD文件定义,可以参阅这三部分的实际结构和详细信息。
配置(config)
其由两个要素组成的:第一个是强制性的,为Kite生成的pXML库提供存储的位置,也可以指定存储库的深度来优化调整导入过程。另一个元素是可选的连接部分,它给出了数据库源的JDBC连接详细信息,并包括连接字符串,用户名和密码 - 如需要,密码可以加密。
1 | |
行提供程序(Rowprovider)
行提供程序负责整合数据源并提供键值对的值,其中Key为列的标题,Value是行的单元格的值。有许多访问数据源的行提供程序,它们是:
- CSV文件 - 读取给定的CSV文件,一次只能处理一个文件;
1 | |
- Excel电子表格 - 读取给定Excel文件表单,一次只能处理一个文件的一张表单;
1 | |
- 数据库 - 执行查询并读取结果,仅作为一个结果集,但它可能来自多张表的复杂的查询结果
1 | |
也有一些行提供程序用来添加值到数据源提取的值,这些是:
- 哈希行提供程序 – 根据行所有值中创建一个哈希值以创建唯一标识,这通常在数据行没有主键的地方使用。
1 | |
- 变量替换行提供程序 - 格式化或替换读取的值,也可以用于在导入过程中插入静态值,例如,我使用它来指定数据源属性的值。
1 | |
rowprocessor(行处理器)
行处理器将行数据的键值对转换为对象的属性或附件,以及与其关联的链接。这里提供了多个行处理器来执行这些转换,每个处理器都在Palantir帮助中有详细说明,我最常用的是:
- 属性行处理器(PropertyRawProcessor)——将属性值添加到对象,如果对象尚不存在,则创建一个新对象;
1 | |
- 时间间隔属性处理器(TimeIntervalPropertyProcessor)- 添加内置日期/时间属性,可以添加到事件和文档中;
1 | |
- 子对象处理器(StubObjectProcessor)和父子关系处理器(ParentChildLinkProcessor)- 它们一起使用来创建对象间的链接。
1 | |
Kite是一个可扩展的平台,可以扩展或重新实现处理器和提供程序; 例如,我曾编写过一个行处理器,它使用一个正则表达式,其中包含一个或多个组,并有多个属性名称,使用相应匹配组的值填充每个属性。这个扩展用于处理HTML 标签,提取URL为一个属性,同时将链接文本提取为另一个属性。
导入/同步
当有了pXML库后,工程师就可以创建一个导入或同步作业来将数据导入到系统中。导入是一个单独运行的作业程序,通常将数据放入新的调查中,供用户在发布之前使用;同步是将数据放入到基础库的一个周期性作业程序。对pXML的任何更新都将在下一次运行时被同步程序进行标识并加载到系统中,除非工程师显式的再次运行导入,否则导入时不会发生这种情况。
Raptor
Raptor是一个补充的软件包,可以用于大型文档存储的部署,例如一个组织的网络驱动器。使用Raptor时,在服务器上安装一个服务,并将给出的共享路径作为Raptor作业程序设置的一部分。然后,Raptor将抓取该目录下的文档,建立索引并把索引保存到服务器中。一旦Dispatch检测到该Raptor服务的存在,Raptor索引也将被包括在前台界面的搜索中。
Phoenix
Phoenix是另一个补充的软件包,它是Palantir用于导入PB级规模、结构化数据的解决方案,如通话记录、交易日志或网络日志。Phoenix为用户提供了对海量数据源快速搜索数据子集的能力,例如给定号码的所有通话记录,然后将该子集导入Palantir的调查进行分析。
插件开发
最后的标准导入机制是使用Palantir开发API,这里唯一的限制是开发人员有能力用Java来开发。助手——Helper(Palantir一种插件类型)一个例子,比如说维基百科搜索助手,它可以提供一个搜索功能并向用户呈现结果列表,然后用户可以选择需要的结果,将整篇文章作为一个文档放进Palantir系统,为文档标记做准备。
在下一篇文章中,我将深入介绍Palantir提供的用于数据分析的应用程序。
Palantir系列文章
- 硅谷最神秘的独角兽Palantir-01
- 什么是Palantir-02
- Palantir本体(Ontology)-03
- Palantir数据集成-04
- Palantir应用程序-05
- Palantir浏览器应用-06
- Palantir图分析应用-07
- Palantir SWOT分析-08
- Palantir分析:商业模式画布、SWOT、垄断特征、以及7个商业模式
